
- Services
- Discovery & Intelligence Services
- Publication Support Services
- Sample Work

Publication Support Service
- Editing & Translation
-
Editing and Translation Services
- Sample Work

Editing and Translation Service
-
- Research Services
- Sample Work

Research Services
- Physician Writing
- Sample Work

Physician Writing Service
- Statistical Analyses
- Sample Work

Statistical Analyses
- Data Collection
- AI and ML Services
- Sample Work
AI and ML Services
- Medical Writing
- Sample Work
Medical Writing
- Research Impact
- Sample Work

Research Impact
- Medical & Scientific Communication
- Sample Work

Medical & Scientific Communication
- Medico Legal Services
- Educational Content
- Academic Editorial Services
- Sample Work
Academic Editorial Services
- Educational Editorial Service
-
Education Editorial Services
- Sample Work
Education Editorial Services
-
- Industries
- Subjects
- About Us
- Academy
- Insights
- Contact Us
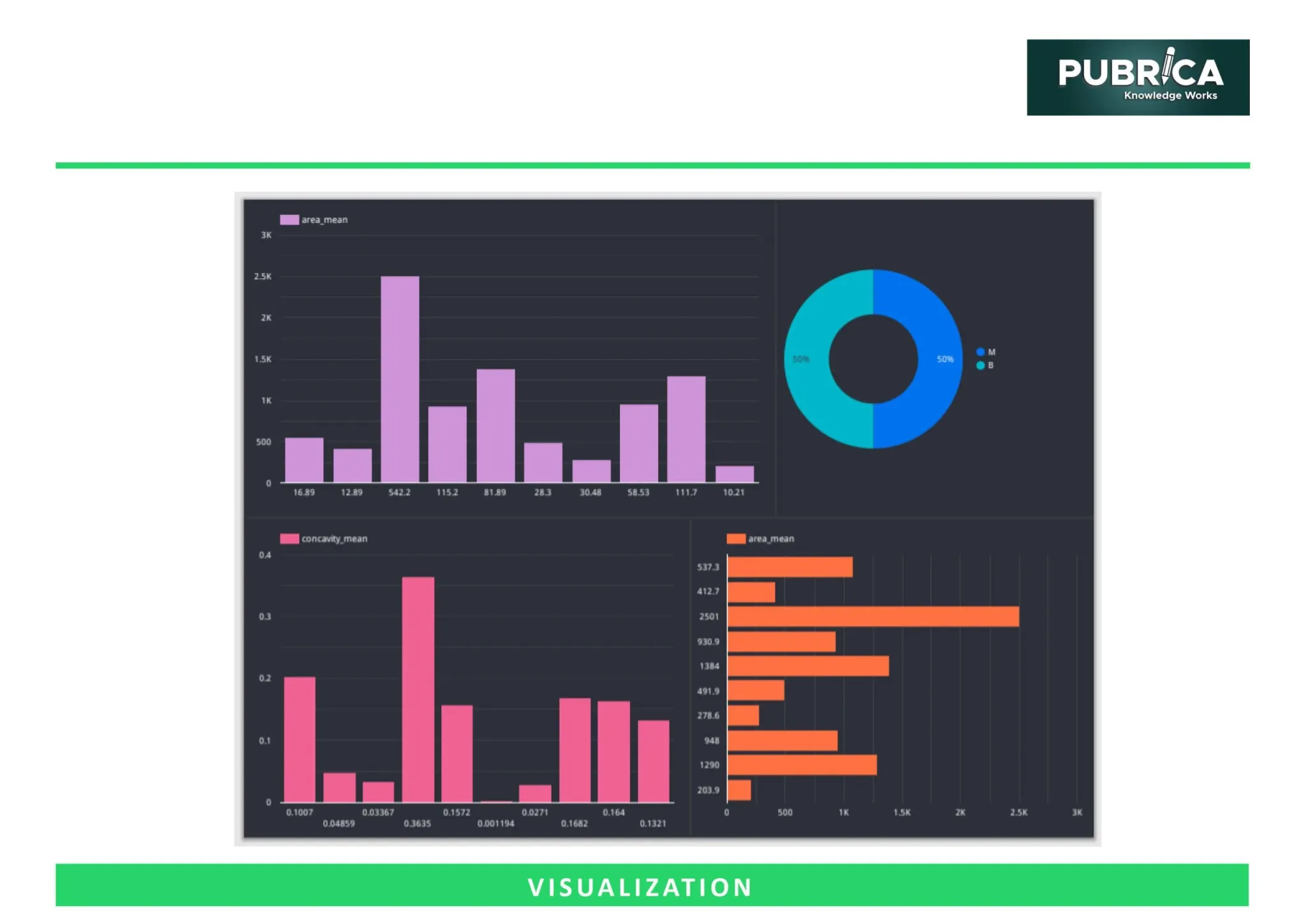
Targeted literature searches are a fundamental part of writing clinical manuscripts that will meet the standards of high-quality journals and contribute meaningfully to evidence-based practice. When physicians write clinical manuscripts, utilizing a targeted literature search can identify high-quality, relevant, and current evidence. While a general literature review is useful, a targeted literature search is specific to the clinical question and should be completed through frameworks established, such as PICO (Population, Intervention, Comparator, Outcome) and PRISMA [1].
A Guide to Understanding Basic Concepts in Bioinformatics
- Home
- Academy
- Research Impact
- A Guide to Understanding Basic Concepts in Bioinformatics
High-Impact Journals
Interesting topics
A Guide to Understanding Basic Concepts in Bioinformatics
Bioinformatics is an interdisciplinary field that draws from biology, computer science, mathematics, and statistics to analyze and interpret biological data. Today, it is of utmost importance to genomics, proteomics, drug discovery, and personalized medicine approaches. The advent of high-throughput sequencing technologies has led to an exponential increase in biological datasets available to bioinformaticians, making bioinformatics an indispensable component of modern research. [1]
- Storing and organizing biological data
- Analyzing DNA, RNA, and protein sequences
- Predicting structures and functions of biomolecules
- Understanding evolutionary relationships
1. Biological Databases
1.1. Table 1: Examples of Common Bioinformatics Databases
| Database | Type of Data | Description |
|---|---|---|
| NCBI GenBank | Nucleotide sequences | Repository for DNA and RNA sequences |
| UniProt | Protein sequences | Comprehensive database for protein function and structure |
| PDB | 3D protein structures | Provides experimentally determined protein structures |
| KEGG | Pathways | Curated database of biological pathways and molecular networks |
2. Sequence Analysis
Sequence analysis is a core area in bioinformatics. This area aims to compare a nucleotide or protein sequence to determine similarities and differences among the sequences, or the relatedness of sequences due to evolutionary forces.[3]
- Global Alignment: The Needleman-Wunsch algorithm
- Local Alignment: The Smith-Waterman algorithm
- BLAST (Basic Local Alignment Search Tool): A common program to use for sequence similarity
3. Structural Bioinformatics
Structural bioinformatics studies 3D structural paradigms of biological molecules to elucidate their function and interaction modes. [4]
- Branches of protein structural levels: Primary, secondary, tertiary, and quaternary
- Homology modeling: Predicting 3D structures based on known and homologous structural templates
- Molecular docking: Predicting an interaction of ligand and protein binding mode.
4. Genomics and Proteomics
Genomics examines the whole genome of an organism, while proteomics studies the entire complement of proteins.[5]
Important Tools in Genomics:
- Genome assembly software: SPAdes, SOAPdenovo
- Gene prediction software: AUGUSTUS, GeneMark
- Functional annotation software: GO (Gene Ontology), KEGG pathways
Key Tools in Proteomics:
- Mass spectrometry data analysis
- Protein-protein interaction networks
- Databases like STRING for interaction mapping
4.1. Table 2: Comparison of Genomics and Proteomics
| Feature | Genomics | Proteomics |
|---|---|---|
| Focus | DNA sequences | Proteins |
| Tools | BLAST, GeneMark | Mass Spectrometry, STRING |
| Applications | Gene discovery, evolution | Protein function, pathways |
5. Bioinformatics Algorithms
The field of bioinformatics increasingly employs algorithms to help us analyze and understand complicated data. Consequently, a lot of work is done using algorithms that fall into several common categories.[6]
- Sequence Alignment: Needleman-Wunsch, Smith-Waterman.
- Clustering: Hierarchical clustering, K-means.
- Phylogenetics: Neighbour-Joining, Maximum Likelihood.
6. Emerging Trends in Bioinformatics
Bioinformatics is evolving rapidly, driven by new technologies and data analytics.[7]
- Next-Generation Sequencing (NGS): Faster, cheaper genome sequencing
- Machine Learning & AI: Protein structure prediction (e.g., AlphaFold)
- Systems Biology: Integration of multi-omics data
- Personalized Medicine: Tailoring treatments based on individual genomic profiles
7. Challenges in Bioinformatics
The storage and management of massive datasets. Integration of data that exists in many forms. Standardizing the analytical pipeline. Computational costs and the need for high-performance computing.[8]
Connect with us to explore how we can support you in maintaining academic integrity and enhancing the visibility of your research across the world!
Conclusion
Bioinformatics combines biology with computer science to help make sense of the increasingly large amounts of biological data. Through sequence analysis (including genomics), structural bioinformatics, and proteomics, researchers can begin to uncover insights about cellular machinery through what makes sense or doesn’t in scientific research, drug discovery, and personalized medicine, among others. The future of bioinformatics rests on the implementation of complex algorithms and AI and greater collaborative work across disciplines to understand complicated biological questions.
A Guide to Understanding Basic Concepts in Bioinformatics? Our Pubrica consultants are here to guide you. [Get Expert Publishing Support] or [Schedule a Free Consultation]
References
- Krutik Patel; A beginner’s guide to bioinformatics. Biochem (Lond) 28 April 2023; 45 (2): 11–15. doi: https://doi.org/10.1042/bio_2022_136
- Ma, L., Zou, D., Liu, L., Shireen, H., Abbasi, A. A., Bateman, A., Xiao, J., Zhao, W., Bao, Y., & Zhang, Z. (2023). Database Commons: A Catalog of Worldwide Biological Databases. Genomics, proteomics & bioinformatics, 21(5), 1054–1058. https://doi.org/10.1016/j.gpb.2022.12.004
- Koonin EV, Galperin MY. Sequence – Evolution – Function: Computational Approaches in Comparative Genomics. Boston: Kluwer Academic; 2003. Chapter 4, Principles and Methods of Sequence Analysis. Available from: https://www.ncbi.nlm.nih.gov/books/NBK20261/
- Soares, C. M., & Lousa, D. (2025). Structural Bioinformatics: exciting times in a rapidly evolving field. FEBS open bio, 15(2), 200–201. https://doi.org/10.1002/2211-5463.13968
- What’s the difference between proteomics and genomics?(n.d.). IDEX Health & Science. Retrieved September 20, 2025, from https://www.idex-hs.com/news-events/stories-and-features/detail/proteomics-vs-genomics
- Hamada, M., & Asai, K. (2012). A classification of bioinformatics algorithms from the viewpoint of maximizing expected accuracy (MEA). Journal of computational biology: a journal of computational molecular cell biology, 19(5), 532–549. https://doi.org/10.1089/cmb.2011.0197
- Sharma, A., Pal, T., Naithani, U., Gupta, G., & Jaiswal, V. (2024). Emerging trends of big data in bioinformatics and challenges. In Intelligent Data Analytics for Bioinformatics and Biomedical Systems(pp. 265–290). Wiley. https://doi.org/10.1002/9781394270910.ch11