

- Services
- Discovery & Intelligence Services
- Publication Support Services
- Sample Work

Publication Support Service
- Editing & Translation
Editing and Translation Services
- Sample Work

Editing and Translation Service
- Research Services
- Sample Work

Research Services
- Physician Writing
- Sample Work

Physician Writing Service
- Statistical Analyses
- Sample Work

Statistical Analyses
- Data Collection
- AI and ML Services
- Sample Work
AI and ML Services
- Research Impact
- Sample Work

Research Impact
- Medical & Scientific Communication
- Sample Work

Medical & Scientific Communication
- Medico Legal Services
- Educational Content
- Industries
- Subjects
- About Us
- Academy
- Insights
- Get in Touch
- Services
- Discovery & Intelligence Services
- Publication Support Services
- Sample Work
Publication Support Service
- Editing & Translation
Editing and Translation Services
- Sample Work
Editing and Translation Service
- Research Services
- Sample Work
Research Services
- Physician Writing
- Sample Work
Physician Writing Service
- Statistical Analyses
- Sample Work
Statistical Analyses
- Data Collection
- AI and ML Services
- Sample Work
AI and ML Services
- Research Impact
- Sample Work
Research Impact
- Medical & Scientific Communication
- Sample Work
Medical & Scientific Communication
- Medico Legal Services
- Educational Content
- Industries
- Subjects
- About Us
- Academy
- Insights
- Get in Touch
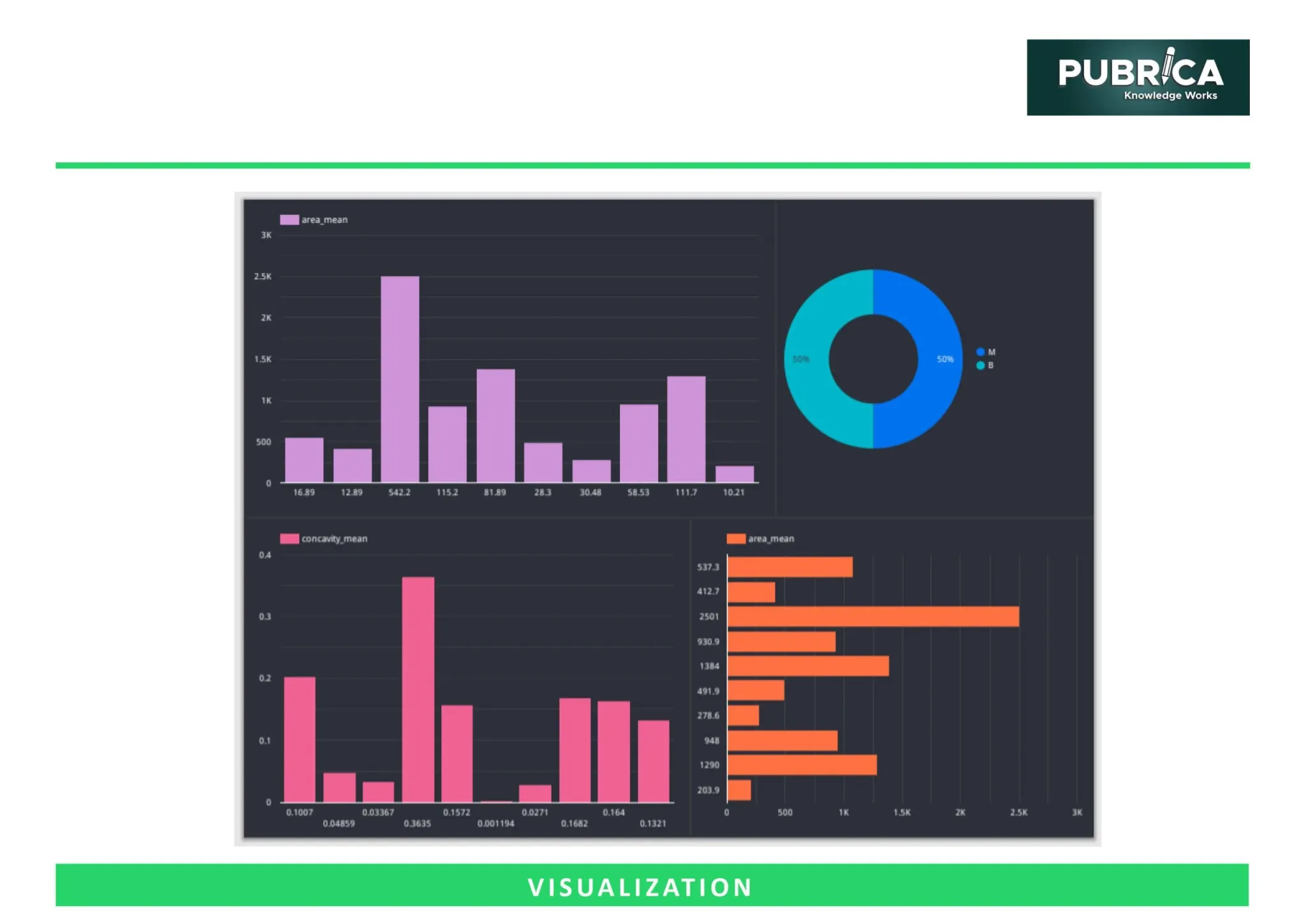
Biostatistics Sample Work
In the data sciences, a variety of regularization algorithms have been proposed to overcome overfitting, leverage sparsity, or enhance prediction. We discuss a variety of techniques within this framework, including penalization, early halting, ensembling, and model averaging, using a wide definition of regularization, which involves regulating model complexity by adding information in order to solve ill-posed problems or prevent overfitting. Aspects of their actual implementation are explored, as well as accessible R-packages and examples. We surveyed three general medical publications to determine the extent to which these techniques are employed in medicine. With the exception of random effects models, it demonstrated that regularization procedures are rarely used in real clinical applications. As a result, we propose that regularization procedures be used more frequently in medical research. The sole disadvantage of regularization procedures in instances when other approaches work well is increased complexity in the conduct of the biostatistics studies, which might provide obstacles in terms of computer resources and skill on the part of the data analyst. Both can and should, in our opinion, be addressed by investing in proper computing infrastructure and instructional resources.
Check our blog to know more about a Meta-analysis and Bioinformatics Assessment of Tumour Mutation in Predicting Immunotherapy Effects

Each order includes
- On-time delivery or your money back
- A fully qualified writer in your subject
- In-depth proofreading by our Quality Control Team
- 100% confidentiality, the work is never re-sold or published
- Standard 7-day amendment period
- A paper written to the standard ordered
- A detailed plagiarism report
- A comprehensive quality report