

How to write the rationale for research?
June 29, 2021
Editing And Proofreading Your Research Paper
July 5, 2021In Brief
Systematic reviews have studied rather than reports as the unit of interest. So, multiple reports of the same study need to be identified and linked together before or after data extraction. Because of the growing abundance of data sources (e.g., studies registers, regulatory records, and clinical research reports), review writers can determine which sources can include the most relevant details for the review and provide a strategy in place to address discrepancies if evidence were inconsistent throughout sources(1). The key to effective data collection is creating simple forms and gathering enough clear data that accurately represents the source in a formal and ordered manner.
Introduction
The systematic review is designed to find all experiments applicable to their research question and synthesize data about the design, probability of bias, and outcomes of those studies. As a result, decisions on how to present and analyze data from these studies significantly impact a systematic review. Data collected should be reliable, complete, and available for future updating and data sharing (2). The methods used to make these choices must be straightforward, and they should be selected with biases and human error in mind. We define data collection methods used in a systematic review, including data extraction directly from journal articles and other study papers.
Data extraction for systemic review
One scientist extracted the characteristics and findings of the observational cohort studies. The mainobjectives of each scientific analysis were also derived, and the studies were divided into two groups based on whether they dealt with biased reporting or source discrepancies. When the published results were chosen from different analyses of the same data with a given result, this was referred to as selective analysis reporting. When information was missing in one source but mentioned in another, or when the information provided in two sources was conflicting, a discrepancy was identified. Another author double-checked the data extraction. There was no masking, and disputes were settled by conversation (3).
Avoiding data extraction mistakes
- Population specification error:The problem of calculating the wrong people or definition rather than the correct concept is known as a population specification error. When you don’t know who to survey, no matter what data extraction tool you use, the data analysis is slanted. Consider who you want to survey. Similarly, having population definition errors occurs when you believe you have the correct sample respondents or definitions when you don’t.
- Sample error:When a sampling frame does not properly cover the population needed for a study, sample frame error occurs. A sample frame is a set of all the objects in a population. If you choose the wrong sub-population to decide an entirely alien result, you’ll make frame errors are a few examples of sample frames. A good sampling frame allows you to cover the entire target community or population.
- Selection error:A self-invited data collection error is the same as a selection error. It comes even though you don’t want it. We’ve all prepared our sample frame before going out on the field study. But what if a participant self-invites or participates in a study that isn’t part of our study? From the outset, the respondent is not on our research’s syllabus. When you choose an incorrect or incomplete sample frame, the analysis is automatically tilted, as the name implies. Since these samples aren’t important to your research, it’s up to you to make the right evidence-based decision.
- Non- response error:The higher the non-response bias, the lower the response rate. The field data collection error refers to missing data rather than an data analysis based on an incorrect sample or incomplete data. It can be not easy to maintain a high response rate on a large-scale survey. Environmental or observational errors may cause measurement errors. It’s not the same as random errors that have no known cause (4).
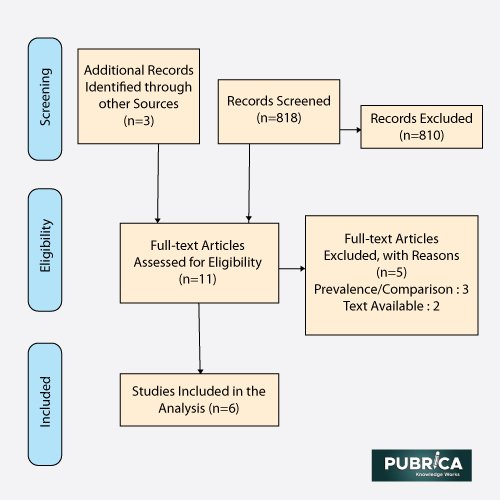
Table: 1 Example for data extraction in the systemic review
They established and used three criteria to determine methodological quality because there was no recognized tool to evaluate the empirical studies’ organizational quality.
- Self-determining data extraction by at least two people
- Definition of positive and negative findings.
- Safety of selective reporting bias in the empirical study
For each study, two authors independently evaluated these things. Since the first author was personally involved in the study’s design, an independent assessor was invited to review it. Any discrepancies were resolved through a consensus discussion with a third reviewer who was not concerned with the included studies (5).
Conclusion
Data extraction mistakes are extremely common. It may lead to significant bias in impact estimates. However, few studies have been conducted on the impact of various data extraction methods, reviewer characteristics, and reviewer training on data extraction quality. As a result, the evidence base for existing data extraction criteria appears to be lacking because the actual benefit of a particular extraction process (e.g. independent data extraction) or the composition of the extraction team (e.g. experience) has not been adequately demonstrated. It is unexpected, considering that data extraction is such an important part of a systematic review. More comparative studies are required to gain a better understanding of the impact of various extraction methods. Studies on data extraction training, in particular, are required because no such work has been done to date. In the future, expanding one’s knowledge base will aid in the development of successful training methods for new reviewers and students (6).
References
- Richards, Lyn. Handling qualitative data: A practical guide. Sage Publications Limited, 2020.
- Muka, Taulant, et al. “A 24-step guide on how to design, conduct, and successfully publish a systematic review and meta-analysis in medical research.” European journal of epidemiology 35.1 (2020): 49-60.
- vanGinkel, Joost R., et al. “Rebutting existing misconceptions about multiple imputation as a method for handling missing data.” Journal of Personality Assessment 102.3 (2020): 297-308.
- Borges Migliavaca, Celina, et al. “How are systematic reviews of prevalence conducted? A methodological study.” BMC medical research methodology 20 (2020): 1-9.
- Lunny, Carole, et al. “Overviews of reviews incompletely report methods for handling overlapping, discordant, and problematic data.” Journal of clinical epidemiology 118 (2020): 69-85.
- Pigott, Terri D., and Joshua R. Polanin. “Methodological guidance paper: High-quality meta-analysis in a systematic review.” Review of Educational Research 90.1 (2020): 24-46.