Deep Learning Over Machine Learning
November 30, 2020
How is Machine Learning Significant to Computational Pathology
December 2, 2020
In-Brief
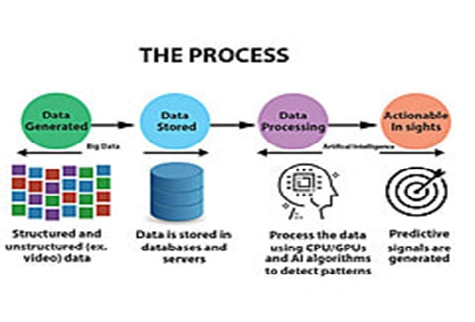
- Over a decade, the “Big data” showcases the rapid increase in variety and volumeof information, particularly in medical research.
- As scientists, rapidly generate, store and analyze data that would have taken many years to compile. “Big data” means expanded and large data volume, possess increasing ability to analyze and interpret those data.
- Each data can benefit from the other, and it can improve clinical practice is explained briefly in pubrica blog for Clinical biostatistics services
Introducing big data
“Big data” is best considered of its purpose. The ultimate characteristic of such experimental approaches is not the vast scale of measurement but the hypothesis-free method to the experimental design. In this blog, we define “Big data” experiments as hypothesis-generating rather than hypothesis-driven studies. They inevitably involve rapid measurement of many variables and are typically “Bigger” than their counterparts driven by a prior hypothesis. They probe the unknown workings of complex systems: if we can measure it all and do so in an attempt to describe it, maybe we can understand it all. This approach is less dependent on prior information and has more significant potential to indicate unsuspected pathways relevant to disease in biostatistics consulting services
In contrast, others argued that new techniques were an irrelevant distraction from established methods. With history, it is clear that neither extreme was accurate. Hypothesis-generating systems are not only synergistic with traditional methods, but they are also dependent upon them. In this way, Big data analyses are useful to ask novel questions, with conventional experimental techniques remaining just as relevant for testing them by using Statistical Programming Services
Development of big data
The development of Big data has drastically approaching to enhance our ability to probe the “parts” of biology may be defective. The goal of precision medicine aims leads the approach one step by making that information of practical value to the clinician. Precision medicine can be briefly defined as an approach to provide the right treatments to the right patients at the right time. For most clinical problems, precision strategies remain yearning. The challenge of reducing biology to its parts, then analyzing which must be measured to choose an optimal intervention, the patient population will get benefits. Still, the increasing use of hypothesis-free, Big data approaches promises to help us reach this aspirational goal using medical biostatistical Services